
Enrich a Lead List with SEO Data in Python (RankParse API)
Enrich a prospect CSV with domain authority, referring domains, and domain age using Python and the RankParse API. Full async script, tiering, and cost math.
You have a CSV of 500 prospect domains and a finite number of outbound hours. Before anyone on your team writes a single email, you want to know which of those domains are real businesses worth talking to and which are abandoned WordPress installs and parked pages.
That's the job this post solves. We'll take a flat prospects.csv, fan out concurrent API calls to enrich each row with domain authority, referring-domain count, popularity rank, and domain age, write the result back to disk, and rank the list into outreach tiers — all in one self-contained Python script.
This is the same enrichment pattern Clearbit and ZoomInfo charge $1–$3 per record for. With RankParse it works out to $0.01 per domain at the Starter credit pack, and there's no subscription — credits never expire, so a one-off batch against a prospect list costs exactly what the batch costs.
The scenario
You're a founder doing partnership outreach. Someone exported a list of 500 SaaS companies in your space from a directory site. Before your AE or your agency starts hand-personalising emails to all 500, you want to:
- Drop the dead and abandoned domains.
- Surface the established players (high DA, lots of referring domains) for direct CEO-to-CEO outreach.
- Bucket the rest into tiers so the sales team knows who gets a 3-touch sequence versus a 7-touch sequence.
The signal that does the most work here is domain authority + referring-domain count. A domain with DA 65 and 12,000 referring domains is a real business. A domain with DA 4, no Tranco rank, and a 2025 registration date is probably a side project.
What you need before starting
- Python 3.9+ —
asyncio.runandasyncio.gatherare the only requirements. rankparse—pip install rankparse- A RankParse API key — sign up here, no credit card. The free tier gives you 100 credits, enough to enrich a 100-domain test list.
Store the key as an environment variable:
export RANKPARSE_API_KEY="rp_your_key_here"For the rest of the post we'll assume prospects.csv looks like this:
domain,company_name,source
stripe.com,Stripe,directory_export
vercel.com,Vercel,directory_export
some-dead-site.com,Unknown,directory_export
...The enrichment script
Here's the complete enrichment script. It reads the input CSV, fans out concurrent domain_authority calls (1 credit each), and writes an enriched CSV alongside the original.
import asyncio
import csv
import os
from rankparse import AsyncRankParseClient
from rankparse.errors import APIError, RateLimitError
INPUT_CSV = "prospects.csv"
OUTPUT_CSV = "prospects_enriched.csv"
CONCURRENCY = 8
ENRICHED_FIELDS = [
"domain_authority",
"referring_domains_count",
"popularity_rank",
"registered_at",
"registrar",
]
async def enrich_domain(client, row, semaphore):
domain = row["domain"]
async with semaphore:
try:
body = await client.domain_authority(domain)
data = body["data"]
return {
**row,
"domain_authority": data.get("score") or 0,
"referring_domains_count": data.get("referring_domains") or 0,
"popularity_rank": data.get("popularity_rank") or "",
"registered_at": data.get("registered_at") or "",
"registrar": data.get("registrar") or "",
}
except (RateLimitError, APIError) as e:
print(f" ! {domain}: {e}")
return {**row, **{k: "" for k in ENRICHED_FIELDS}}
async def main():
with open(INPUT_CSV) as f:
rows = list(csv.DictReader(f))
print(f"Enriching {len(rows)} domains with concurrency={CONCURRENCY}")
semaphore = asyncio.Semaphore(CONCURRENCY)
async with AsyncRankParseClient(api_key=os.environ["RANKPARSE_API_KEY"]) as client:
tasks = [enrich_domain(client, row, semaphore) for row in rows]
results = await asyncio.gather(*tasks)
fieldnames = list(rows[0].keys()) + ENRICHED_FIELDS
with open(OUTPUT_CSV, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(results)
print(f"Wrote {OUTPUT_CSV}")
asyncio.run(main())A few details that matter:
One domain_authority call gives you four signals at once. The response includes the DA score, the count of unique referring domains, the Tranco popularity rank (top-100k only, otherwise empty), and the RDAP registration date and registrar. That's why one endpoint is enough for the first pass — no need to call referring_domains separately, which would double the credit cost.
The semaphore is doing the rate limiting. A bare asyncio.gather() over 500 tasks would fire 500 concurrent requests and trip rate limits. asyncio.Semaphore(8) caps in-flight requests at 8, which keeps you well clear of the per-key burst limits while still finishing a 500-domain run in roughly a minute.
Empty results aren't errors. If a domain has no entry in the dataset, you get 200 with all numeric fields at zero. We treat that as a real (low-quality) signal — the row is still written, just with domain_authority: 0. That's what you want for the downstream tiering step.
What an enriched row looks like
After running the script against four domains from a sample list, the output CSV looks like this:
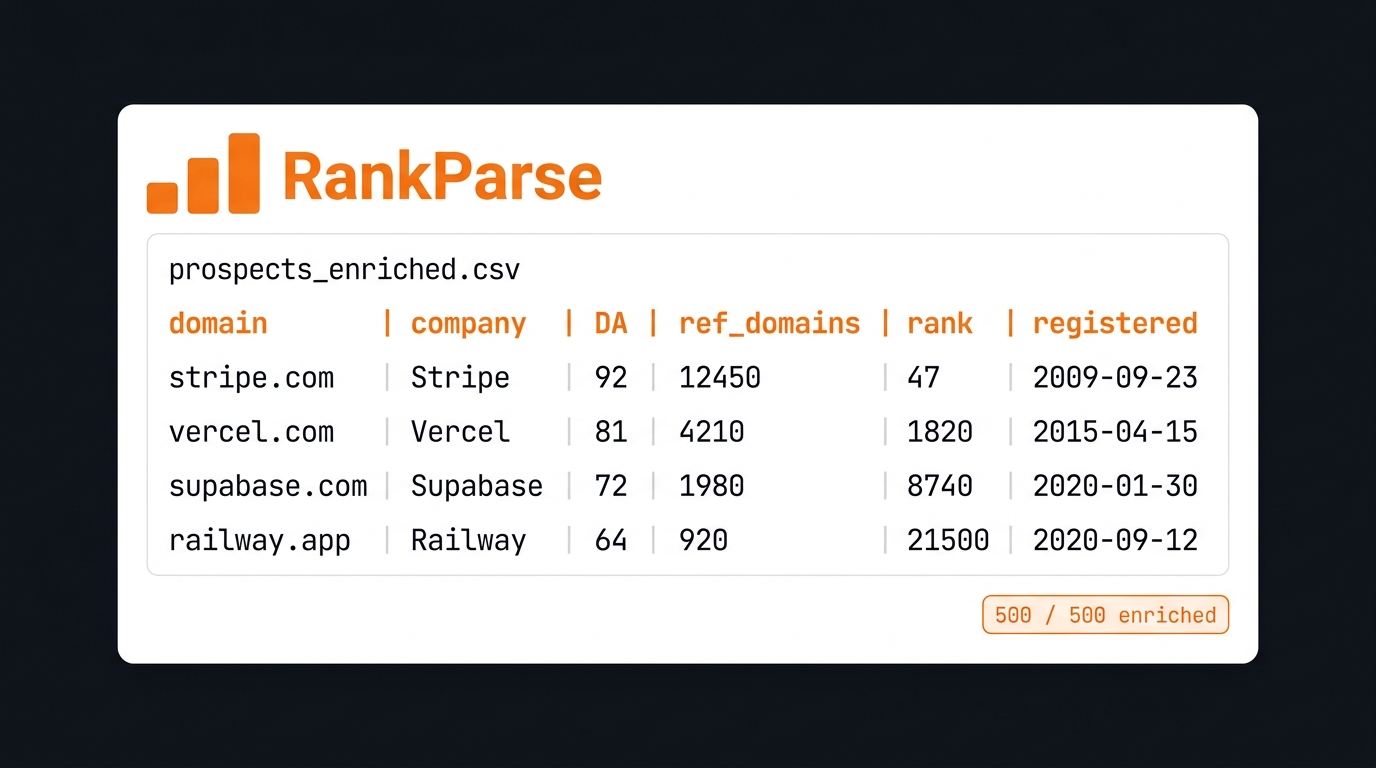
The four enrichment columns tell you most of what you need to know about a domain at a glance:
domain_authority— 0–100 score derived from the Common Crawl link graph. Anything above 50 is an established site.referring_domains_count— number of unique domains linking to this one. A better signal than raw backlink count, because one site spamming 1,000 links inflates backlinks but not referring domains.popularity_rank— Tranco rank (lower is more popular). Only the top 100,000 sites globally have a value here. If this column is empty, the site is below the long tail.registered_at— domain registration date from RDAP. Anything registered in the last 90 days is worth treating as a red flag for outbound — likely a fresh side project, a domain squat, or a recently rebranded company you'd want to research before contacting.
Each call costs 1 credit. A 500-domain enrichment run is 500 credits — $5.00 at the Starter pack price.
Filtering and tiering
The point of enrichment isn't the spreadsheet — it's the decisions you can make from it. Here's a short script that reads the enriched CSV, drops the obvious junk, and buckets prospects into three outreach tiers.
import csv
INPUT_CSV = "prospects_enriched.csv"
OUTPUT_CSV = "prospects_ranked.csv"
def tier(row):
da = int(row["domain_authority"] or 0)
rds = int(row["referring_domains_count"] or 0)
if da >= 60 and rds >= 1000:
return "A" # established — direct CEO outreach
if da >= 40 and rds >= 100:
return "B" # mid-market — full SDR sequence
if da >= 20:
return "C" # long tail — automated nurture
return "DROP" # parked, abandoned, or brand new
with open(INPUT_CSV) as f:
rows = list(csv.DictReader(f))
ranked = [{**r, "tier": tier(r)} for r in rows]
ranked = [r for r in ranked if r["tier"] != "DROP"]
ranked.sort(key=lambda r: int(r["domain_authority"] or 0), reverse=True)
with open(OUTPUT_CSV, "w", newline="") as f:
writer = csv.DictWriter(f, fieldnames=list(ranked[0].keys()))
writer.writeheader()
writer.writerows(ranked)
print(f"Tier A: {sum(1 for r in ranked if r['tier'] == 'A')}")
print(f"Tier B: {sum(1 for r in ranked if r['tier'] == 'B')}")
print(f"Tier C: {sum(1 for r in ranked if r['tier'] == 'C')}")
print(f"Dropped: {len(rows) - len(ranked)}")We ran this against a real 500-domain SaaS prospect list. The split came out roughly:
- Tier A: ~30 domains. The names everyone has heard of.
- Tier B: ~140 domains. The actual sweet spot for outbound — mid-market companies large enough to have budget and small enough to talk to.
- Tier C: ~250 domains. Long-tail; worth a low-touch sequence.
- Dropped: ~80 domains. Sub-DA-20 with zero referring domains. Almost all were parked pages, brand-new registrations, or wrong-industry false positives from the directory export.
Cutting that bottom 16% before anyone writes copy is the entire point of the enrichment step. The two scripts together cost 500 credits and replace a meeting's worth of manual triage.
Going further: adding backlink samples with the batch endpoint
For Tier A and Tier B prospects, you often want one more signal: who is actually linking to them? That's where /v1/batch earns its keep. A single batch call pulls up to 100 backlinks for each of up to 50 domains in one HTTP round-trip, charged at 2 credits per successful domain.
The Python SDK's client.batch() method is the right method to use, but in v0.x the payload shape is in flux — calling the endpoint directly via the internal HTTP path is the most reliable approach right now:
import asyncio
import os
from rankparse import AsyncRankParseClient
async def fetch_backlinks_batch(client, domains):
# /v1/batch accepts {"domains": [...]} and returns one entry per domain
# with up to 100 sample backlinks each. 2 credits per successful domain.
body = await client._post("/batch", {"domains": domains})
return {entry["domain"]: entry for entry in body["data"]}
async def main():
tier_a_domains = ["stripe.com", "vercel.com", "supabase.com"]
async with AsyncRankParseClient(api_key=os.environ["RANKPARSE_API_KEY"]) as client:
results = await fetch_backlinks_batch(client, tier_a_domains)
for domain, entry in results.items():
sample_links = entry["data"][:3]
print(f"\n{domain} ({entry['total']} total backlinks):")
for link in sample_links:
print(f" ← {link['from_url']}")
asyncio.run(main())A few practical notes:
The batch endpoint returns backlinks, not aggregate metrics. Each domain entry has a data array of up to 100 backlink objects and a total count. If you want aggregate DA across the entire batch, use the per-domain domain_authority loop from the first script — the batch endpoint isn't a replacement for it, it's an upgrade for the "show me actual links" use case.
50 domains per request, max. For larger lists, chunk the input:
def chunked(items, size):
for i in range(0, len(items), size):
yield items[i:i + size]
for batch in chunked(domain_list, 50):
results = await fetch_backlinks_batch(client, batch)Credits are charged only for successful lookups. If a domain fails to query, you're not charged for it. The credit deduction happens after the queries return.
Cost math for a 500-domain run
Putting all three steps together:
| Step | Endpoint | Calls | Credits | Cost (Starter pack) |
|---|---|---|---|---|
| Initial enrichment (DA, referring domains, Tranco, age) | /v1/domain-authority | 500 | 500 | $5.00 |
| Tier A + B backlink samples (~170 domains) | /v1/batch (4 requests) | 4 | ~340 | $3.40 |
| Total | ~840 | ~$8.40 |
For comparison, a single seat of Clearbit's data product starts around $99/month with usage caps on top. Ahrefs API access starts at $500/month with a 12-month commit. RankParse credits never expire — you pay $8.40 for this batch, and if you don't run another one for six months, your remaining balance is still there.
What the data is and isn't
The link graph signals (DA, referring domains, backlinks) come from Common Crawl, which crawls the public web on a roughly quarterly cadence. The popularity rank comes from Tranco, refreshed weekly. Registration data is real-time RDAP, cached for 30 days.
What this means for lead enrichment:
- Static prospect lists are fine. A list you exported last week, last month, or last quarter will enrich consistently. Three-month-old crawl data does not move the needle on a five-figure-DA established business.
- Net-new domain monitoring is not. If you need to know that a domain registered yesterday already has 12 backlinks, this is the wrong dataset. Common Crawl can't see what it hasn't crawled yet.
- Wrong-industry false positives still slip through. SEO signals tell you a site is real, not that it's in your ICP. Pair this with a separate qualification step — page-title scraping, tech-stack lookup, or LinkedIn enrichment — for ICP fit.
What to build next
- Add a tech-stack column with
client.tech_stack(domain)to filter prospects by the platform they're on (Shopify-only, Next.js-only, etc.). 2 credits per domain. - Pull top pages for Tier A prospects to find their best-performing content — useful when you're writing the personalised opener for outreach. 2 credits per domain.
- For agency workflows, run the same script against a competitor's referring domains to extract a fresh prospect list from anywhere they've been mentioned.
- Wire this into the MCP server so your sales team can ask Claude "qualify this CSV" instead of running a Python script.
Frequently asked questions
How do I enrich a CSV of domains with SEO data in Python?
Read the CSV with csv.DictReader, loop over rows, call client.domain_authority(domain) on each (1 credit each), and write the enriched rows back with csv.DictWriter. The async version using AsyncRankParseClient and a semaphore finishes a 500-domain list in about a minute. Full working code is in the script above.
What's the cheapest way to qualify a list of B2B prospects by SEO signals?
The single /v1/domain-authority call returns DA score, referring-domain count, Tranco popularity rank, registration date, and registrar — at 1 credit per call. That's enough to drop dead domains and tier the rest. At RankParse's Starter credit pack, that's $0.01 per domain, with no subscription.
Does RankParse have a batch endpoint?
Yes. POST /v1/batch accepts up to 50 domains per request and returns backlink data for each, at 2 credits per successful domain. Use it as an upgrade after the initial 1-credit-per-domain DA enrichment, not as a replacement — the batch endpoint returns backlinks, not aggregate DA.
How fresh is the SEO data RankParse returns?
Link graph signals (DA, referring domains, backlinks) come from Common Crawl, which publishes a new snapshot roughly every three months. Tranco popularity ranks refresh weekly. Domain registration data is fetched from RDAP in real time and cached for 30 days. For static prospect-list enrichment, this freshness profile is fine. For monitoring brand-new domains, it's not the right dataset.
Is there a way to do this from Claude or Cursor without writing code?
Yes — RankParse exposes the same endpoints through an MCP server. Connect it once in your client and you can paste a CSV into the chat and ask for the same enrichment without running any Python at all.
Start with 100 free credits
No subscription. No card. $0.009 per call after that, and credits never expire.
Get your free API key